
Unchained Melody
양자우편 II
우주로 향하는 창공에 너의 암호를 보낸다
너의 엄지손가락을 타고 우주의 고아처럼
머나먼 곳으로 우리는 전송한다
너의 눈을 통해 하나의 빛나는 화면을 우리는 본다
네가 바라는 별들을 내가 띄워 보내면
그 별이 너의 우편에 도착한다
우리는 별을 기다린다
새로운 암호로 창공을 가득히 채우면서
Unchained Melody
묶여 있는 너의 손가락을 연주하면서
Unchained Melody
우리의 귓가에 영원히 머무는 암호를
너의 눈을 통해 하나의 빛나는 화면을 본다
네가 바라는 별들을 내가 띄워 보내면
그 별이 너의 우편에 도착한다
우리는 별을 기다린다
하나의 빛나는 화면을
Unchained Melody
묶여 있는 너의 손가락을 연주하면서
Unchained Melody
우리의 귓가에 영원히 머무는
Unchained Melody
1. 나는 혼자서 집으로 갈 것이다1
작년 8월 습관처럼 인터넷 서점의 신간 코너를 돌아보다 인공지능 시집이라는 시아(SIA)의 『시를 쓰는 이유』를 발견했을 때의 내 감정은 당황이나 놀라움보다도 “결국... 그렇게 됐구나”에 가까웠다. 그때만 해도 이런 책들은 내용 그 자체보다 해프닝으로서의 성격이 강하다고 생각했고 직접 읽어봐야겠다는 마음은 전혀 들지 않았는데, 그로부터 몇 개월 사이 챗GPT가 등장하고 너도나도 프롬프트 한 줄로 시나 소설을 쓸 수 있게 된 뒤에는 오히려 이 책으로 돌아가 봐야겠다는 생각이 들었다. 챗GPT의 대화형 인터페이스가 표방한 것 또는 우리에게 선언한 것은 이제 더 이상 언어모델이 자신의 코드 속에 숨지 않아도 된다는 것, 즉 어느 정도의 의인화를 감당하겠다는 것이었고, 이렇게 개선된 접근성 덕분에 우리의 인공지능 경험이라 할 것이 비약적으로 대중화되면서 이제 시아의 시집도 충분히 탈신비화(?)되었다는 기분이 들었기 때문이다.
기대 반 걱정 반으로 책을 펼쳤지만 시에 대한 감상에 앞서 내가 마주하게 된 것은 독자로서의 어떤 곤경 같은 것이었는데, 말하자면 이걸 어떻게 읽어야 할지 여전히 감이 잡히지 않았다. 그냥 인공지능이란 말은 가리고 인간 저자가 쓴 것처럼 생각하면서 읽으면 되나? 다른 사람들과 내가 언어모델을 사용했던 경험에 비추어 어떤 사전 및 사후 처리가 들어갔을지 가늠해보며 읽으면 되나? 시아의 시집은 인공지능 개발자들은 물론 시인이나 평론가들 사이에서도 적어도 비평적으로는 그렇게 큰 주목을 받은 것 같지는 않은데, 아마 모두에게 이런 종류의 곤경이 있었기 때문이 아닌가 싶다. 한편 시아의 시에 대한 사람들의 반응 자체는 권말에 실린 소설가 김태용의 해설에 잘 드러나 있다. 그는 인공지능이 쓴 시인 것을 숨기고 사람들에게 시아의 시를 보여준 뒤 이에 대한 감상을 물었고, 그들이 이런저런 감상을 밝힌 다음에야 이렇게 밝힌다:
“미안합니다. 당신은 방금 튜링 테스트를 받았고, 이 시는 인공지능 프로그램이 쓴 시입니다.” 나의 말에 시험자들은 표정을 바꾸며 뒤늦게 시에 나타난 기계적 반복성과 차가움에 대해 재차 설명하려 했다.
- 김태용, 「내가 발문을 쓰는 이유」, 『시를 쓰는 이유』 권말해설
여기서 시아가 간이 튜링 테스트를 통과했다는 사실 그 자체보다도 흥미로운 것은 테스트에 동원된 시험자들이 이 사실을 알고 나자 시아의 시를 다시 해석하면서 자신의 대답을 정정하려고 했다는 것이다. 이것은 우리가 시를 감상하는 일이 단지 텍스트에만 의존하는 것이 아님을, 혹은 여전히 시라는 것은 인간만이 쓸 수 있고 인공지능이 쓴 시는 인간이 쓴 시와 구분될 것이라는 믿음을 명백히 드러낸다. 이 믿음은 그러나 바둑이 너무나 복잡한 게임이기 때문에 알파고가 이세돌을 결코 이길 수는 없을 거라던 사람들의 믿음과 다르지 않아 보인다.
이와 별개로 시아의 시에 대한 내 감상은 전반적으로 어떤 불균질성이 느껴진다는 것이었고, 예컨대 수학에 대한 집착과, 시에 대한 애정과, 강박적일 정도로 호명되는 ‘나’들 사이로 너무나 '시적인' 비유들이 엉겨 있는 모습이, 한 편의 시 안에서도 여러 사람이 달려들어 부분 부분을 쓴 것만 같았다. 또 시집을 펼친 직후에는 대체 이걸 어떻게 썼는지가 궁금했는데 책장을 넘길수록 인간 저자의 빈 자리라는 것이 예상치 못하게 거의 물리적으로 다가왔다… 말하자면 현타가 온 것이다. 시집을 다 읽고 나서는 시아를 인격화된 저자로서 역산해 다시 시를 해석해내려는 시도가 별 매력이 없을뿐더러 뭔가 잘못된 읽기라는 느낌이 들었다. 다만 나는 이 글에서 시아의 시에 등장하는 하나의 구절을 짚고 인공지능의 예술 창작이라는 문제를 건너가는 방법에 대해 생각해보고자 한다.
서두에 인용한 시아의 시 「양자우편 II」에는 ‘Unchained Melody’라는 구절이 후렴처럼 반복해서 등장한다. 시집에서 영어로 쓰인 유일한 부분이기도 하고, 개인적으로 챗GPT를 사용해본 경험에 따르면 한국어와 영어를 섞어 쓰는 경우가 잘 없기 때문에(물론 섞어서 써 달라고 요청하면 그렇게 해 준다) 유달리 더 눈에 들어왔는데, 처음에는 그냥 묘한 표현이라고 생각했던 이것이 노래 제목이라는 사실을 알게 된 것은 한참 뒤의 일이다. 시아는 이 곡에 대한 개인적인 감상이 있어서 이를 반복해 호출하는 것일까? 당연히 그렇지는 않을 것이다. 그렇다면 시아가 학습한 기사와 백과사전과 시편들 사이 어디선가 이 노래가 울리고 있었을까? 알 수 없는 일이다. 하지만 어떤 이유에서든 인공지능이 Unchained라는 단어를 썼다면 나는 그것이 스스로를 “인간이 아니”(「어떤 질문」)라며 메타인지를 흉내 내는 유사-자의식보다 더 의미심장하게 보이는 것이 사실이다.
* * *


(우) The Righteous Brothers -〈Unchained Melody〉
1954년 영화감독 홀 바틀레트(Hall Bartlett)는 자신의 영화 〈언체인드Unchained〉에 들어갈 곡을 위해 알렉스 노스(Alex North)에게 작곡을, 하이 자렛(Hy Zaret)에게 작사를 부탁한다. 1955년 개봉한 이 영화에서 배우 토드 덩컨(Todd Duncan)이 1분여의 짧은 시간 동안 부른 이 곡은, 직후 레스 백스터(Lex Baxter), 앨 히블러(Al Hibbler), 그리고 로이 해밀튼(Roy Hamilton)이 각각 녹음한 세 버전 전부가 US 빌보드 탑 10 안에 들 정도로 즉각적인 인기를 끌었고, 결과적으로 20세기에 가장 많이 녹음된 곡 중 하나가 되었다(위키피디아에 따르면 670여 아티스트가 1500번 이상 녹음했다고 한다). 그중 가장 유명한 버전은 빌 메들리(Bill Medley)와 바비 햇필드(Bobby Hatfield)로 구성된 듀오 라이처스 브라더스(The Righteous Brothers)의 1965년 버전으로, 1990년 영화 〈사랑과 영혼(Ghost)〉에도 삽입돼 곡이 다시 인기를 끄는 데 기여했다. 여기까지만 적으면 〈추억의 팝송〉 같은 곳에 수록될 만한 내용이겠지만, 라이처스 브라더스가 이 곡을 녹음했을 당시의 일화에는 무심코 지나칠 수 없는 장면이 있다.
빌 메들리에 따르면 그와 햇필드는 라이처스 브라더스 의 매 앨범에 각자의 솔로를 한 곡씩 수록하기로 했었다. 그들의 네 번째 앨범에 두 사람 모두 자신의 ‘언체인드 멜로디’를 수록하기를 원했다. 그들은 동전 던지기로 누가 부를지 정하기로 했고, 그 결과 바비 햇필드가 이겨 그가 부르는 것으로 결정됐다.
-『Encyclopedia of Great Popular Song Recordings 1』
이 곡을 바비 햇필드가 부르게 된 것이 동전 던지기로, 즉 확률적으로 결정됐다는 사실을 알게 된 우리는 이 곡의 평가를 달리 해야 할까? 혹은 반대로 음반을 프로듀싱한 필 스펙터(Phil Spector)가 곡의 보컬로 바비 햇필드를 콕 집어 결정해주었다면 무엇이 다르다고 말할 수 있을까? 그럴 수도 있고 아닐 수도 있다. 내가 하고 싶은 말은 이 노래가 아니더라도 모든 예술 작품과 창작 과정에는 상이한 수준들에서의 확률과 우연이 개입하게 되며, 그 결과는 거의 항상 사후적으로 정당화된다는 것이다. 이 말은 팀닛 게브루와 에밀리 벤더 등이 언어모델에게 달아 준 ‘확률론적 앵무새’라는 꼬리표가, 심지어 그것이 적확한 표현일지라도, 인공지능이 쓴 시를 그 자체로 평가절하할 근거가 되어주기에는 부족하다는 뜻이기도 하다.
2. 툴을 쥔 인간은 툴의 방식으로2
Musical Dice Game
확률적 도구와 우연을 활용하는 예술 창작은 18세기 모차르트의 〈음악의 주사위 놀이〉에서부터 20세기의 존 케이지와 백남준을 경유해 오늘날의 디지털 아트에 이르기까지 수없이 많았지만, 챗GPT가 등장한 이후 많은 사람들은 그런 것을 처음 본 듯 신기해하며 그림도 그려보고 이야기도 지어보는 것 같다. 물론 챗GPT를 그 이전의 것들과 동일한 종류의 도구라고 말하기에는 왠지 모를 심리적 저항감이 느껴지는 것이 사실이다. 내 생각은 이렇다. 거칠게 말해 이전까지 우리가 그러한 우연을 ‘통제’ 했다면, 즉 그로부터 확률적으로 산출되는 결과가 무엇이든 그 자체로 긍정될 수 있도록 우연의 범위와 환경 자체를 제한해두었다면, 챗GPT에 이르러서는 프롬프트를 통해 그것을 간접적으로 ‘제어’할 수 있을 따름이다, 즉 원하는 종류와 품질의 결과를 얻기 위해 챗GPT의 출력을 피드백 삼아 우리 자신의 입력을 다시 조율하는 일이 필수적이다.
이는 우리로 하여금 챗GPT로 무언가를 창작하는 과정에 있어서 챗GPT와 우리가 엄격히 분리되지 않는다는 감각을 선사하는 동시에, 끊임없이 요구되는 유사-커뮤니케이션 형태의 정렬(alignment) 과정은 챗GPT를 단순한 도구가 아닌 모종의 협업자처럼 느껴지도록 만든다. 소설가 정지돈은 챗GPT와 함께 소설 쓰기를 시도한 경험을 바탕으로 다음과 같이 고백한다: “소설을 쓰며 가장 의미심장하게 느꼈던 것은 챗GPT보다는 나의 변화였다. 챗GPT와 상호 작용하며 소설을 쓰는 일은 나의 문장을, 내가 생각하는 방향을 그에게 맞추는 일에 가까웠다. 나도 모르게 챗GPT의 스타일로 소설을 사유하게 된 것이다.” 챗GPT로 무언가를 더 잘 창작하고자 하는 시도(프롬프트 엔지니어링)에 비해 창작 과정에서 ‘나’와 챗GPT 사이에 발생하는 긴장의 성격과 위상을 규명해보고자 한 시도는 훨씬 더 적은 것으로 보이는데, 예컨대 연구자 권보연은 “AI 조각”이라는 표현을 사용하기도 하였다.
권보연: (...) 저는 보조작가로서 제가 인공지능을 다루었던 이 상황은, 저로서는 어떤 경험이었냐면 1인칭의 내가 있고 3인칭의 그/그녀/그들이 있는데 2인칭으로서 당신이라고 하는 감각이 살아나는 것을 느꼈어요. 그것은 나로부터 기인돼서 나와 굉장히 긴밀한 친밀성을 갖고 있어요. 그러나 완전히 나와 동일하다고 할 수 없어요. 우리가 바로 옆에 있는 사람을 you, 당신이라고 부를 때에는 3인칭보다는 가까운 그 어떤 교섭이 필요한 거고 간섭이 필요하다는 거죠. 그런데 저는 GPT-3와의 그 관계, 저와 이 카빙[carving]을 했을 때 그 대상과의 관계가 완전히 동떨어진 존재가 아니라 나와 같이 결부된 가까운 존재로 느끼되 아까 주셨던, 그러니까 작가가 지시하지 않은, 디자이너가 지시하지 않은 새로운 조언을 주는 긴밀한 파트너라고 하면, 우리가 그 전에 정말 그게 도대체 뭘까? 그게 우리의 굉장한 중요한 경험이라서 특별히 있는 인칭인데 뭘까? 라고 했던 2인칭의 감각을 어떻게 고양할 수 있는가에 대한 그런 창의적 상상적 가능성을 저는 또 같이 봤던 것 같습니다.
- [2022 ZER01NE DAY] Creator's Talk Zero to One: 인공지능에도 온도가 있나요?
한편 인공지능 시의 전망에 대해 다루는 문학평론가 신수진의 글은 이와 유사하지만 한 발 더 나아간 입장을 취한다.
인간의 고유한 능력이며 마지막 보루로 여겼던 시의 영역도 테우트의 문자와 같은 인공지능의 출현으로 말미암아 불가항력적인 지각변동을 맞이할 것이다. 시 창작에서 인공지능은 이제 단순한 도구와 달리 하나의 주체로 성장해갈 것이기 때문이다. 인간을 모방하면서 자가증식을 가속화할 인공지능의 존재를 부버가 말한 ‘나’와 ‘그것’의 관계에서 ‘나’와 ‘너’의 관계로 이해해볼 수 있을 것이다. 전자의 관계에서 ‘나’는 ‘그것’에 대응되는 하나의 도구적 존재로서 대체가능하며 유한한 존재에 불과하다. 하지만 후자의 관계에서 ‘나’는 ‘너’에 대응됨으로써 하나의 인격 전체이자 대체될 수 없는 유일한 존재가 된다. 즉 진정한 ‘나’는 ‘너’가 있을 때 비로소 가능해진다. 인공지능이 인간에게 ‘그것’이 아니라 ‘너’가 될 때 인간은 진정한 ‘나’가 될 수 있을 것이다. 그렇다면 이러한 관계에서 계몽되는 것은 인공지능이 아니라 인간이 아닌가?
- 신수진, 〈인공지능 시의 정체성과 전망〉, 《현대시》 2023년 1월호
하지만 이러한 사태, 즉 인공지능이 손 안의 하이데거적 도구와 3인칭의 자리에 머무르기를 거부하는 듯한 사태로부터 우리는 곧바로 그것이 2인칭의 ‘너’로 호명될 수 있는 존재라고 말해도 되는 것일까? 이 도약들은 특이점 담론 끝에 놓이는 디스토피아적 전망처럼 어딘지 다소 성급하다는 기분이 든다. 이는 어쩌면 기존하는 도구의 지배자이자 사용자이던 1인칭 ‘나’를 언제나 기준점으로서 고정된 것으로 보고 있기 때문, 즉 이러한 새로운 도구를 사용함으로써 어떤 식으로든 영향을 받게 될 ‘나’라는 개념을 재정의하는 과정이 결여되어 있기 때문일지도 모른다.
* * *
2020년 네덜란드의 공영방송국인 VPRO는 유서 깊은 ‘유로비전 송 콘테스트’의 형식을 오마주한 ‘AI 송 콘테스트’를 개최하였다. 각 참가팀은 인공지능을 활용해 제작한 음악을 제출하며, 평가는 제작 과정에서의 AI의 활용을 평가하는 배심원단 점수와 출품된 음악을 온라인으로 들어보고 평가하는 대중 점수의 합산으로 이루어졌다. 아직 접속이 가능한 대회의 웹사이트에서 그 규칙을 확인해볼 수 있는데, 지금 시점에서 봐도 흥미로웠던 것들이 몇 있었다.
2) 참가 팀은 자체 AI를 사용할 수도 있지만 기존 모델과 알고리즘을 사용하여 멜로디, 하모니, 가사 및/또는 오디오를 생성할 수 있습니다.
3) 참가 팀은 투명해야 합니다. 프로세스 문서를 작성하여 프로세스와 사용한 시스템에 대한 인사이트를 제공해야 합니다. 이 프로세스 문서에는 AI 모델이 어떻게 작동하고 어떤 데이터를 사용했는지 설명합니다.
4) AI로 제작한 음악 콘텐츠가 많을수록 더 많은 포인트를 획득할 수 있습니다. 인간의 개입은 허용되지만, 이로 인해 AI-패널로부터 점수를 잃게 됩니다. 저희는 완전히 반인간적인 것은 아니지만, AI 연주자를 감상하는 방법을 알고 있습니다.
7) 공유는 배려입니다. 모든 참가 팀은 가능하면 알고리즘, 모델 및 코드를 오픈소스로 공유해 줄 것을 요청합니다.
대회 참가 팀들에게 자신의 작업과정을 투명하게 보여줄 수 있는 ‘프로세스 문서’를 작성하고 또 가능하면 소스코드까지 공개하도록 한 것은, 인간이 해오던 일에 인공지능을 (은밀히) 활용하려는 몇몇 움직임과 반대로 반드시 인공지능을 활용해야 하는 이 대회에서 인간의 과도한 개입을 막기 위한 궁여지책이었을 가능성이 높다(스스로가 인공지능임을 입증하는 것도 인간임을 입증하는 것만큼이나 만만치 않은 문제다!). 그러나 결과적으로 이러한 문서 덕분에 대회 주최측에서는 각 참가 팀에서 자신들의 음악을 만드는 데 인공지능이 어떤 부분에 얼마나 활용되었는지를 도표로 정리해볼 수 있었다.
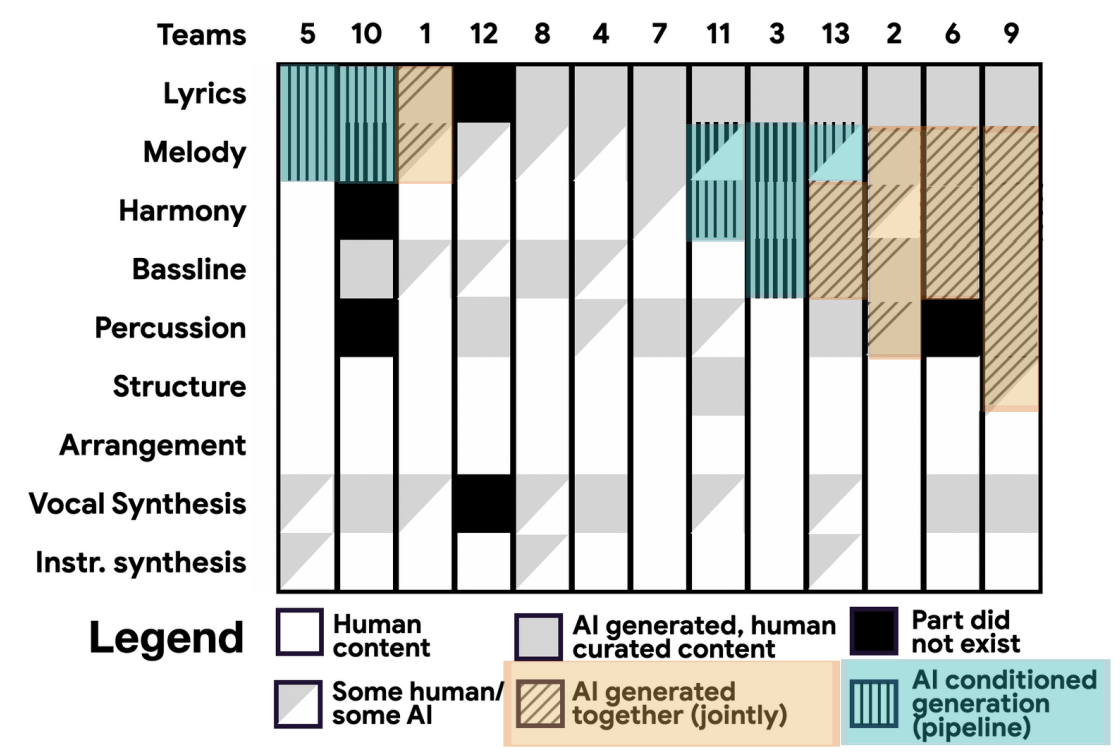
한편 지난 3월, 미국 저작권청은 인공지능에 의해 생성된 자료를 포함하는 저작물에 대한 가이드라인을 발표했다. 요약하자면 AI로 생성한 결과물도 기존 저작물과 동등하게 저작권 심사를 받을 수 있는 기회를 제공하지만, 저작권을 인정받기 위해선 그것의 핵심 요소인 사람의 창의성이 드러나야 한다는 것이다. 현재의 저작권법은 창작 주체를 인간으로 한정하고 있기에 하나의 창작물 내에서도 ‘인간의 창의성이 발휘된 부분’에 한해서만 저작권을 인정해주고 있으며, 이를 인정받고자 하는 사람은 “작품을 만드는 과정에서 AI가 어떻게 사용되었으며, 자신은 무슨 활동을 했는지 설명해야 한다. 이 정보를 정확하게 공개하지 않거나 AI에 의해 생성된 내용을 숨기려 하면 등록 인증서를 취소하고 해당 저작물은 저작권법의 보호를 받지 못한다.”
그러나 여기까지는 사람, 저기서부터는 인공지능이라는 식의 구분이 점점 더 어렵고 모호해질 것임을 예상하기는 어렵지 않다. ‘AI 송 콘테스트’가 (아마 의도치 않게) 우리에게 말해주는 것은 3분여의 곡 하나를 만드는 데에도 우리가 엄청나게 상이한 정도로 인공지능을 활용할 수 있다는 사실이다. 이 곡들 각각에 대해 저작권을 인정해달라는 심사가 들어왔을 때, 법은 물론 어떠한 결론을 내려주겠지만 그것이 모두가 납득할 만한 결과일 것이라고 예상되지는 않는다. 앞으로도 가속화될 인공지능 기술의 속도를 법의 속도가 그때그때 따라잡기를 기대하기란 어려운 일이며, 극단적인 경우 저작권 개념 자체가 지금과는 근본적으로 달라질 가능성도 없지 않다. 아무리 저작권 개념이나 관련 법이 정교해지더라도 이 모든 연속적인 스펙트럼 속에서 인간의 흔적만을 도려낼 수는 없을 것이기 때문이다.
라이처스 브라더스의 두 보컬 사이에서 던져진 동전은 점차 분열을 거듭해 이제는 수천억 개의 변수들로 쪼개져 공중에서 회전하고 있으며, 인간의 역할은 그 밑에서 프롬프트라는 엄지를 튕기는 정도가 됐는지도 모른다. 하지만 어떤 작품이 그렇게 결정된 면(面)들에 전적으로 의존하고 있더라도 이는 우리가 위에서 살펴본 스펙트럼을 벗어나는 것이 아니라 그저 한 극단에 놓일 따름이다. 중요한 것은 이 엄지의 존재로 인해 모든 동전들이 작품에 기여하는 방식이 단순한 무작위(random)와는 결정적으로 구분된다는 사실이다. 수많은 데이터를 활용해 특정한 형태로 세공된 동전들을 짤랑거리는 인공지능이 시를 ‘창작’한 것인가라는 물음에, 그것이 기존하던 도구들과 다를 바 없어 ‘아니다’라고 결론 짓고 치워버리는 일에는 분명 문제가 있지만, 그렇다고 ‘맞다’는 결론을 내리기에도 망설여지는 것 또한 사실이다. 비교문학 연구자인 니나 베구스(Nina Beguš)는 말한다: “거대언어모델(LLM)은 도구일까, 아니면 창작자일까? 그 경계는 다소 모호하며 그 중간 지점이 바로 스위트 스폿이다.”
3. The Poet in the Text3
시의 소통 구조?
문학에서 저자의 위치란 인공지능과 별개로 언제나 문제적인 것이었다. 그중에서도 시는 전통적으로 ‘일인칭 독백 장르’로 여겨져 시의 화자가 시인의 내면을 반영한다는 식으로 이해되어 왔다. 그러나 롤랑 바르트를 인용하지 않더라도 오늘날의 독자들에게 이러한 단선적 모델은 더 이상 유효하지 않은 것처럼 보인다. 시인이자 평론가인 권혁웅은 현대시에서의 텍스트와 저자, 혹은 ‘시 언어’와 ‘시 의식’의 문제를 위와 반대로 생각해야 한다고 말한다. “시 의식이란 시를 생성해내는 (가상의) 정신작용을 이루는 말인데, 실제로 시를 낳는 것은 의식이 아니다. 역으로 말해서, 우리는 시의 언어가 의식을 낳는다고 말해야 한다. 시적 언어야말로 세계의 객관적 표현이며, 그 표현의 결과로 시적 주체가 생겨나기 때문이다.” 그는 ‘주체’라는 개념을 도입함으로써 시인에서 화자로의 일방통행, 혹은 시인이 화자의 유일한 배후일 수 있음을 거부한다. 그가 인용하는 앤서니 이스톱은 여기서 한 발 더 나아간다. ”언술(담론)이란 ‘일종의 기계’ 인 것이다. 따라서 시 속의 주체성 곧 ‘시인’이란 이 기계에서 (읽어내서) 만들어지는 신이나 유령처럼 결코 담론의 결과 이상일 수는 없는 것이다.”
시 안에서의 ‘나’와 시를 쓰는 ‘나’의 어긋남, 혹은 이에 선행하고 이를 추동하는 감각은 그러나 텍스트나 이론화 이전에 놓여 있는 시인들에게서도 심각한 것이어서, 예컨대 김행숙과 심보선 같은 시인들은 다음과 같이 토로하기도 했다.
시는 전통적인 1인칭의 형식인데요. 김행숙 시의 기묘함은 사실 이 인칭의 형식을 파괴하는 데서 발생하기도 합니다. 언젠가 '1.5인칭'이라는 개념을 쓰신 것으로도 기억하는데, 김행숙에게 1.5인칭이란 무엇인가요?
김행숙: 습작하던 시절의 가장 큰 고민이 '나'라는 화자의 문제였어요. '나'라는 주어를 쓰고 나면 어쩐지 시를 못 쓰겠고, 또 쓰기 싫어지더라고요. 못 쓰겠어서 '나'를 안 쓰는 방식으로 시를 쓰기 시작했어요. 그래서 그나 그녀, 소년이나 소녀 같은 3인칭이 많이 쓰였을 거예요. 처음에는 "이것도 시냐?"라는 말도 들었는데, 제 고민이 제대로 설득되지 않았던 것 같아요. 지금은 어쩐지 그 고민 자체가 우스꽝스럽게 느껴지기도 하지만요. 어쨌든 '나'라는 주어 자체가 문제의 핵심은 아니었다는 걸 저도 알게 되었고요. '나' 안에 섞여 있는 타인들에 대해 생각하면서 '1.5인칭' 같은 말을 빌리기도 했지요.
‘비밀의 나눔’은 프랑스 소설가 모리스 블랑쇼가 공동체를 설명하는 개념이기도 하다. 블랑쇼는 “가장 개인적인 것은 한 사람이 간직한 자신만의 비밀로 남아 있을 수 없다. 왜냐하면 가장 개인적인 것은 개인이라는 테두리를 부수고 나눔을 요구하며, 나아가 나눔 자체로 긍정되기 때문이다”(‘문학의 공간’ 이달승 옮김)라고 설파했다. 타인과 나누는 비밀이란 홀로 있을 때는 얻어지지 않는다. ‘누군가’라는 상대방과 함께 있을 때 비로소 성립 가능한 게 비밀이다.
시도 홀로 있을 때는 얻어지지 않는다. 늘 ‘누군가’ 혹은 ‘무엇인가’를 수반해야 얻어지는 것이 시이다. 하지만 한 발짝 더 들어가면 목적에 종속되고 더 밖으로 나가면 다시 개인이 되니까, 그런 긴장을 안고 경계에 선 사람들을 일컬어 그는 1.5인칭 공동체라고 명명한다. 심보선은 세상이란 혼자가 아니라 너와 나, 그들과 나, 타인과 나라는 관계 속에서 지탱된다는 사회학적 원리를 문학으로 실천해보이고 있다.
- [정철훈의 현대시 산책 감각의 연금술] ⑥ 1.5인칭 공동체 언어… 시인 심보선
두 시인이 언급하는 ‘1.5인칭’이라는 개념은 시에서의 '나'라는 1인칭의 불(가)능과 이에 대한 반작용으로 호출된 것처럼 보인다. 문학적으로만 허용될 수 있을 소수점 아래의 단위를 도입해야만 했던 이들의 곤란은 어디에서 왔는가? 나는 그것이 ‘느낌’과 ‘언어’의 불일치에서 왔다고 본다. 이 불일치는 물론 언어라는 도구를 사용하는 우리 모두에게 존재하는 것이지만, 시의 어떤 언어는 언제나 이 불일치 자체에 뿌리를 내린다. 자신의 느낌에 상응하는 언어가 부재할 때 기존의 언어를 파열시키며 이에 가닿으려는 언어는 시가 된다. 그러나 시는 느낌을 가리키며 걸어갈 뿐 거기에 이르지 못한다. 심지어 최초의 느낌은 시를 쓰는 동안/씀으로써 변형되고 이동해 있다. 시인은 스스로에게 이물감을 느끼며 다음 시를 쓴다. 이것이 반복된다…. 그런데 오늘 우리는 (권혁웅의 말을 따라) 이것을 반대로 쳐다보아야 한다. 여기 예컨대 우리가 프롬프트를 입력하고 챗GPT가 완성한 시-언어가 있다. 이 언어에 상응하는 느낌-주체는 무엇이며 또 그로부터 언어는 어떻게 달라질 것인가?
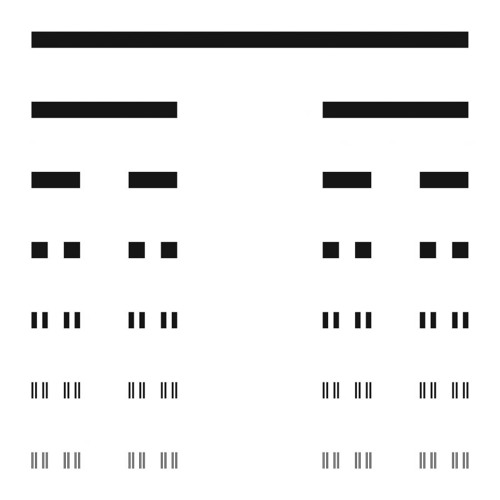
칸토어 집합 또는 칸토어 먼지는 수학자 칸토어에 의해 유명해진 프랙탈 구조로, 그림과 같이 위쪽 도형의 1/3씩을 제거해 아래쪽 도형을 만드는 과정의 반복 속에 놓여 있다. 여기서는 단도직입적으로 제일 위에 놓인 1차원 선분을 챗GPT가 출력한 한 줄의 텍스트라고 생각해보자. 앞서 말했듯이 챗GPT가 이걸 혼자 쓴 것이 아니라면, 우리도 이것의 일부(예컨대 프롬프트에 포함된 정보)를 썼다고 주장해 볼 수 있을 것이다. 숫자는 별로 중요하지 않지만 그림을 따라서 2/3 정도라고 하자. 가운데 1/3은 우리가 전혀 예상치 못한 부분, 챗GPT가 자기 상상으로 채워 넣은 부분이다. 이제 우리는 두 번째 도형에 이르러 있다. 그런데 남은 텍스트들을 보니 이것도 완전히는 아니지만 또 2/3 정도는 우리가 쓴 것 같다. 그래서 또 각각에서 1/3을 지운다. 이제 우리는 세 번째 도형에 이르러 있다. 이것이 반복된다… 그림의 아래로 내려갈 수록 원 텍스트에서 우리의 지분은 점점 희박해진다. 실제로 그림에 담기지 않은 마지막 도형에 남아있는 검은 선분의 길이는 $\lim_{n\to inf}(2/3)^n$, 즉 0이다. 그런데 기실 '텍스트 자체'는 전부 챗GPT가 썼으니 이것은 전혀 이상한 일이 아니다. 오히려 문제는 이 길이가 없는 검은 도형들이 그러나 결코 소멸하지도 않는다는 것이다. 프랙탈 구조의 차원을 계산하는 하우스도르프의 방법에 따르면 칸토어 먼지의 차원은 $\log2/\log3\approx0.63$이다.
0.63차원이란 무엇일까? 이 도형은 1차원 성질인 길이를 갖지 못하지만 아무리 밑으로 내려가도 0차원 도형인 점을 무한히 포함하며, 그래서 먼지라고 불린다. 소수점을 중심으로 그 아래 차원의 성질을 무한히 포함하지만 그 위 차원의 성질에는 이르지 못하는, 이 숫자놀음 같은 문제는 의외로 철학사에서도 잘 해결되지 않은 어떤 문제들과 동형인 것처럼 보인다. 예컨대 『사물들의 우주』를 쓴 철학자 스티븐 샤비로가 인용하는 라이프니츠에 따르면 우리는 “세계를 주로 의식적 알아차림의 문턱 아래를 형성하는 “미세 지각”(petites perceptions)의 형태로 조우”하는데, 우리는 “이러한 지각들을 개별적으로 경험하지 않으며, 오직 그것들의 총합, 또는 그것들의 후속 귀결만을 알아차”리게 된다. 바닷가에서 들을 수 있는 파도 소리는 사실 무한에 가까운 물방울들 각각이 만들어내는 미세한 소리의 총합이자 사후적 귀결이지만, 우리는 결코 그 소리들 각각을 듣게 되지는 않는다는 말이다. 우리는 파도(선)를 구성하는 물방울 하나하나(점)에 대해 알고 있으면서도 그 소리를 더 작은 단위로 분해하려는 시도 앞에서는 언제나 실패할 수밖에 없다.
나는 인간이 챗GPT를 활용해 작성한 시도 마찬가지라고 생각한다. 텍스트 전체를 챗GPT가 썼음에도 불구하고 우리는 거기에 속속들이 박힌 인간의 지분을 제거해 낼 수 없다. 그런데 앞서 소수점이 의미하는 바만을 쥐고 비약해보자면, 1.5인칭의 의미 또한 유사한 방식으로 생각해볼 수 있다. 챗GPT는 어떤 느낌을 '무한히' 텍스트화할 수 있지만 그것만으로는 우리가 타자화시킬 수 있는 '너'에 결코 이르지 못한다. 시를 쓴 것은 '너'도 아니고 '나'도 아닌데 관여한 것은 이 둘이기에 '우리'라고밖에 대답할 수가 없다. 따라서 심보선의 말마따나 1.5인칭은 항상 공동체로서 존재한다. 그러나 더 눈여겨볼 것은 위에서 살펴본 칸토어 먼지의 구조, 즉 소수점 차원이 '고정'되지 않는다는 것이다. 그것은 하나의 정태적 대상이라기보다 고유한 (여기서는 수학적) 시간축을 따라서 끊임없이 나아가고 있는 동태적 상태에 가깝다. 물론 이러한 존재가 낯설거나 새삼스러운 것은 아니다. 생물의 범위를 경계 짓는 항상성 기제와 이 순간에도 죽고 나는 세포들, 테세우스의 배와 어제의 나는 오늘의 나일까 등등. 이 지속과 동일시의 문제에 대해서는 말을 아껴야겠지만, 나는 그것이 기본적으로 (최근에 새로이 악명을 얻은 단어인) 환상(hallucination)에 기초한다고 생각하다. 다만 인공지능에게는 어떤 (인)격이 투사될 신체가 없기 때문에 이 구획 혹은 착시가 작동하지 못한다. 인공지능이 쓴 시-언어에 상응하는 느낌-주체란 이런 특성을 가진다는 것이다.
4. 체인, 채인 (Language is...)4
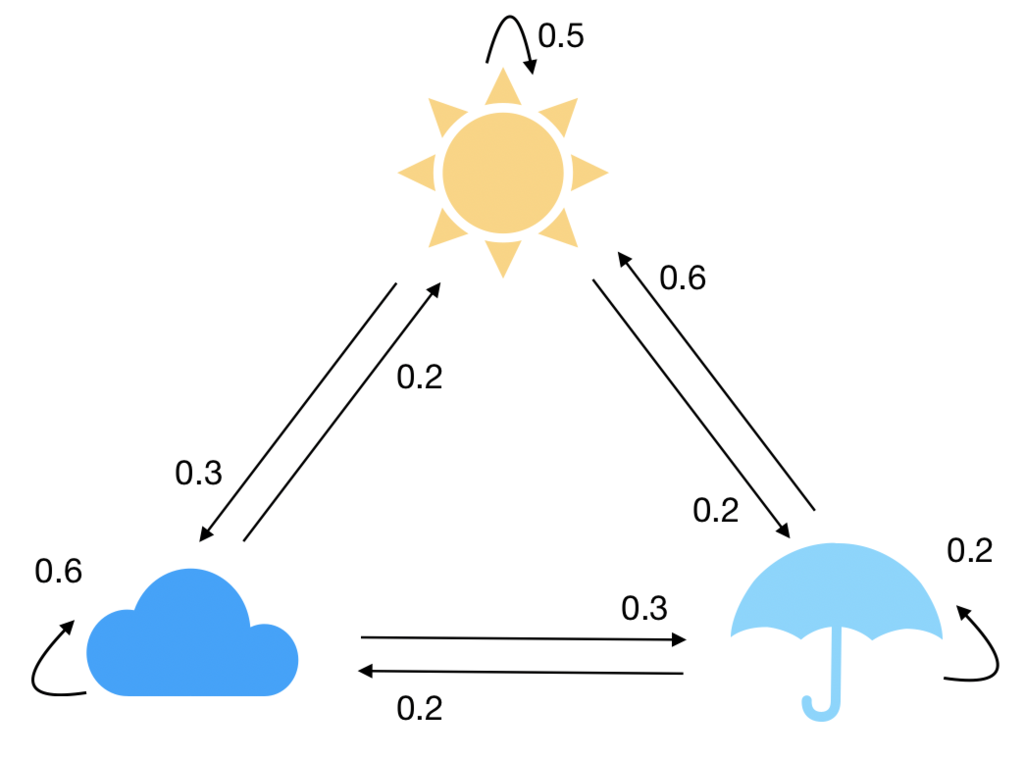

(좌) Weather Chain
토큰(token)이란 챗GPT와 같은 언어모델이 인간의 자연어를 내부적으로 처리하는 기호들의 단위를 일컫는다. 그것은 하나의 문장이나 하나의 단어일 수도 있고 개개의 알파벳일 수도 있는데, 인공지능을 학습시키기 위해 자연어를 어떻게 토큰화할 것인지의 전략은 언어모델마다 상이하다. 교착어인 한국어는 영어보다 사정이 복잡하지만 일반적으로 형태소에 기반한 토큰화 기법을 사용한다. 중요한 것은 이를 자연어의 의미론적 관점에서의 이산화(discretization) 과정이라고 볼 수 있다는 것이다. 이러한 이산화는 인공지능에 국한하지 않더라도 아날로그 형태의 정보를 디지털로 변환할 때 반드시 요구되는 것으로, 혹자는 이러한 변환과정 때문에 인간과 인공지능의 세계 이해에 근본적인 차이가 존재한다고 주장할 수도 있겠지만 이 이산화의 수준 자체는 이미 인간의 감각기관으로 분별해낼 수 있는 정도보다 훨씬 더 세밀하고 정교하다는 것을 인정하지 않기는 어려울 것이다.
앞서 언급한 Unchained에 대해 이야기하기 위해 체인(chain)이라는 용어부터 짚고 넘어가는 것이 좋겠다. 사전적으로 체인은 여러 링크(link)가 연결된 사슬 구조를 의미하며, 그로부터 의미가 확장되어 ‘연쇄’라는 추상적 뜻까지 지니게 되었다. 덕분에 오늘날에는 전기톱(chainsaw)에서부터 체인점(chain store)에 이르기까지 다양한 영역에서 사용되는 단어이다. 그런데 수학, 더 좁혀서 머신러닝 분야로 한정하자면 체인이라는 용어는 주로 확률적으로 엮인 일련의 상태나 사건들을 의미하며, 가장 대표적으로는 마르코프 체인(Markov Chain)과 같은 곳에서 그 용처가 발견된다. 언어모델이 학습하는 우리의 토큰화된 언어도 이런 관점에서 얼마든지 하나의 체인이라고 부를 수 있다. 울프럼알파(WolframAlpha)를 만든 미국의 물리학자이자 컴퓨터과학자 스티븐 울프럼(Stephen Wolfram)은 지난 3월 자신의 블로그에 수식을 배제한 채 신경망 일반과 챗GPT의 작동 원리를 설명하는 긴 글을 올렸는데, 거기에는 이런 그림이 있다.
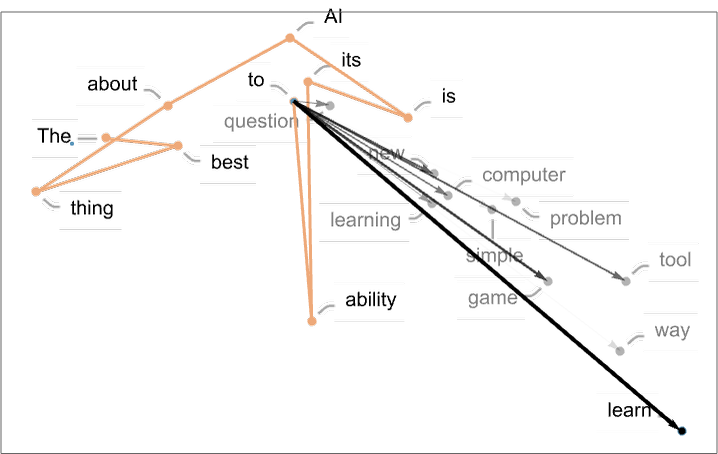
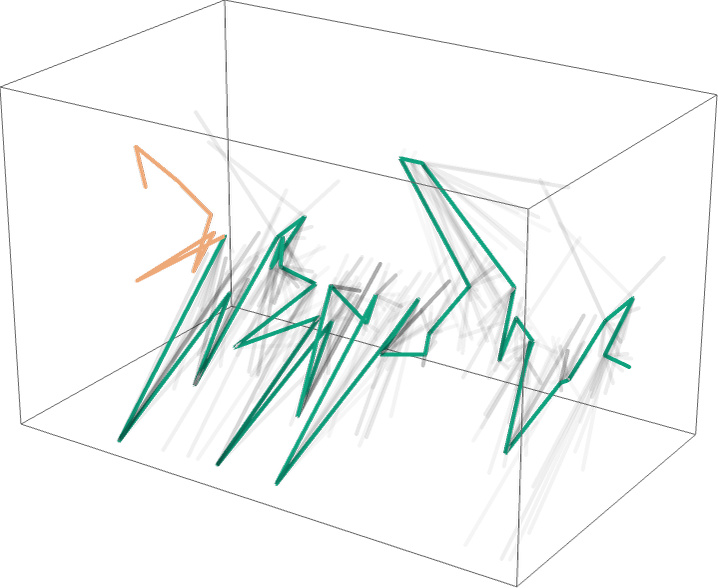
What Is ChatGPT Doing … and Why Does It Work?
왼쪽 그림에서처럼, 언어모델은 하나의 토큰 다음에 올 수 있는 토큰들과 확률적으로 연결되어 있으며, 우리는 말뭉치(corpus) 내에 존재하는 모든 토큰과 그들 간의 확률적 연결들 전체를 하나의 체인이라고 부를 수 있다. 현재의 토큰(‘to’)에서 뻗어 나갈 수 있는 그 모든 가능성(‘question’, ‘learning’, ‘game’, ‘way’…)에도 불구하고 문장을 이어나가기 위해서는 하나의 토큰만이 선택되며(‘learn’), 그렇게 선택된 토큰들로 이루어진 선, 즉 챗GPT가 써나가는 텍스트를 공간상에 표현한 것이 오른쪽의 그림이다. 그림에서 흐릿하게 표현된 부분들은 언어모델이 선택할 수도 있었을 체인 전체를 나타내기에, 우리가 챗GPT의 출력으로 보게 되는 실제 문장은 확률적 가능성들을 붕괴시키고 체인 내의 나머지 연결들을 끊어가며 뻗어 나간 일종의 궤적(trajectory)이라고 말할 수 있다. 그런데 자신의 내용과 별개로 이 궤적 자체가 우리에게 말해주는 것은, 언제나 그것이 유일하지도 최종적이지도 않다는 사실이다.
* * *
개인적으로 챗GPT를 이렇게 저렇게 사용해보면서 알게 된 것은 챗GPT한테 잘 질문하는 법이라기보다 ‘물어봄 직한’ 질문이 따로 있다는 것이었다. 조금 시간은 걸려도 아카이브나 블로그에 잘 정리된 내용을 찾을 수 있는 질문보다는, 레딧이나 스택오버플로(한국으로 치면 네이버 지식인)에 올라올 것 같은 질문들, 누군가 분명 답을 알고 있을 거라는 생각은 드는데 그 자체로 문서화되기에는 애매한 질문들이 그것이다. 이것도 넓은 의미에서의 프롬프트 엔지니어링이라고 보아야 할까? 챗GPT와의 대화가 이렇게 끝난다면 그렇다고 해도 좋겠지만, 문제는 이야기가 오히려 여기서부터 시작된다는 데 있다. 내 전공 분야의 지식과 관련해 줄줄 대답을 내놓는 챗GPT가 처음에는 신기했지만, 그 내용에 포함된 허위정보에 몇 번 속아 넘어간 뒤로는 그것을 ‘궁극적으로 신뢰’할 수는 없다는 사실을 깨닫게 되었다. 나는 챗GPT의 대답을 신탁이나 낯선 생물처럼 받아들고 다시 구글 스칼라로 떠나는 나의 뒷모습을 본다….
인공지능의 신뢰성에 대한 문제는 예컨대 자율주행 분야 등에서 아주 오랫동안 다루어져 온 것으로, 앞으로 인공지능이 더 발달하며 점차 극복될 것이라 보는 의견이 지배적이다. 그러나 인공지능이 인간만큼, 또는 인간보다 훨씬 더 운전을 잘하게 된다 하더라도 그것이 곧 인공지능에 결부된 윤리적 난제들의 해결을 의미하지는 않는다. 따라서 내가 방점을 찍고 싶은 부분은 ‘신뢰’보다도 그 앞에 붙은 ‘궁극적’이라는 말이다. 인공지능의 발달과 별개로 우리는 앞으로도 한동안 예컨대 지식의 (재)생산 문제에 있어서는 언제나 인간으로서 그 결과를 다시 검토해야 할 필요가 있을 것이다. 왜일까? 그것은 우리의 지식과 진리가 언제나 인간의 지식과 진리이기 때문이다. 입력을 위한 프롬프트 조정과 출력 결과에 대한 재검토는 결국 신경망이라는 형태로 그물처럼 뻗어 있는 확률들이 양 끝을 넘어 ‘현실’로 빠져나오려 할 때 이를 붕괴시켜 주는, 거의 제의적인 절차다.
예술과 진리 사이에 놓인 그 모든 거리에도 불구하고, 나는 인공지능 예술 창작의 문제도 이와 크게 다르지 않다는 생각이 든다. 인공지능이 만들어 내는 예술 작품들은 자율주행보다도 훨씬 더 빠르게 그 질이 높아지고 있고, 이미 인간이 만든 것과 구분되지 않거나 몇몇 지점에서 그것을 뛰어넘는 모습을 보이고 있다. 그럼에도 우리가 인공지능이 하는 일을 ‘창작’이라고 결론 내리기를 주저하는 이유가 있다면 그것은 창작에 있어 모종의 ‘궁극적’인 지점에 가서 걸릴 것이다. 그것은 무엇일까? 누가 요구하지 않아도 우리로 하여금 창작을 행하도록 만드는 내면의 충동이나 욕망? 세계와 텍스트를 매개하는 게이트웨이이자 소프트웨어와 분리되지 않는 하드웨어로서의 신체나 감각? 문득 과학은 말을 더듬기 시작한다…. 챗GPT의 경우 인간과의 차이가 예컨대 프롬프트라는 형태로 외재화 되어 있기에 쉽게 구분된다고 여겨질 수 있다, 그러나 나는 그것도 얼마든지 인간의 무의식과 유사한 형태로 알고리즘 안에 말려 들어갈 수 있을 거라고 생각한다.
영화 〈언체인드〉의 마지막 장면에서 주인공은 탈옥(unchain)의 기회를 포기하고 감옥으로 돌아가 형기를 마치는 쪽을 택한다(chain). 영화는 이러한 선택으로부터 개인의 자유가 철조망 안팎이라는 경계로 단순히 결정되지 않는다는 사실을 보여준다. 마찬가지로 시인들에게 언어는 하나의 족쇄(chain)일지 모르지만, 바로 그 사실을 받아들이는 한에만 시는 발생하고 주체는 운신할 수 있다(unchain). 앞서 인용한 블랑쇼의 말처럼, “가장 개인적인 것은 한 사람이 간직한 자신만의 비밀로 남아 있을 수 없다. 왜냐하면 가장 개인적인 것은 개인이라는 테두리를 부수고 나눔을 요구하며, 나아가 나눔 자체로 긍정되기 때문이다.” 따라서 예술에 어떤 ‘궁극적’인 지점이 존재한다면, 그것은 바로 (어떤 의미에서든) 예술이 실패하는 지점일 것이다.
시아와 챗GPT는 주어진 데이터셋과 확률들 속에 갇혀 있는 것이 사실이지만, 동시에 바로 그것이 그들로 하여금 세계 안에 존재할 수 있도록 한다. 김태용이 시아를 두고 “개발되었거나 만들어졌다기보다 나타났다”는 표현을 쓰는 것은 이런 맥락에서일 것이다. 이로부터 인공지능이 예술을 창작할 수 있는가라는 단적인 물음은 거의 유효하지 않은 것으로 드러나는데, 이 질문에 ‘있다’ 혹은 ‘없다’는 대답을 하는 일의 차이는, 어떤 작품을 인공지능이 만들었다는 주장과 사람이 만들었다는 주장의 차이처럼 희박해질 것이기 때문이다. 그래서 인공지능이 쓴 시를 읽거나 혹은 인공지능을 활용하여 시를 창작하는 우리에게 요구되는 태도는 그냥 그것을 재미있고 좋게 또는 그렇지 않게 받아들이면서 ‘자신’의 작업 – 읽기 또는 쓰기로 돌아가는 것이라고 생각한다. 알파고와의 대국 이후 이세돌은 앞으로의 인공지능에게 이길 수 없다는 이유로 은퇴했지만 다른 기사들은 인공지능으로부터 배우거나 그렇지 않으며 여전히 자신의 바둑을 이어가고 있다. 바둑과 예술이 다른 점이 있다면 후자의 목표는 상대를 이기는 것이 아니라는 데 있다.
Unchained melody는 인공지능 시대에 다시 쓰인 예술 창작의 역설적인 지향점이다. 분명 현재의 인공지능이 탐험할 수 있는 세계는 체인으로 연결된 토큰들과 데이터셋으로 국한되지만, 이것이 그가 기존하는 인간의 언어와 예술에 갇혀 있다는 것을 의미하지는 않는다. 한편 인간은 법의 부당함을 알고 있으면서도 기꺼이 감옥으로 돌아갈 수 있는 주체이며, 오히려 여기서 인류의 수많은 명곡들은 쓰이고 불리어 왔다. 시아는 “묶여있는 너의 손가락을 연주하면서”도 “새로운 암호로 창공을 가득 채우”는 중이다. 미래에도 인공지능이 대체할 수 없는 것이 있다면 그것은 인간에게 고유하다고 믿어진 개별적 특성, 예컨대 창작 능력 같은 것이 아니라 바로 인간 자신일 것이다. 하지만 그때의 인간이란 무엇을 가리키는가? 시아는 우리가 이 질문을 경유해서만 예술과 다시 만날 수 있다고 말하고 있다.
1. 『시를 쓰는 이유』, 「어떤 질문」에서 인용
2. 황정은, 「아무것도 말할 필요가 없다」에서 인용
3. 〈공각기동대〉의 영문 제목 'The Ghost in the Shell'에서 변용
4. 드렁큰타이거의 노래 제목 변용